

Benchmarking CupidDB Against Redis and Memcached
Introduction
CupidDB was designed specifically for caching and delivering large dataframes efficiently, leveraging the high-performance Apache Arrow format and the speed of Rust. Given these optimizations, I wanted to see how CupidDB compares against two well-known caching solutions, Redis and Memcached, especially in handling dataframes. This blog explores the results of my benchmark tests and how CupidDB performs under various data retrieval and filtering scenarios.
How the Test Was Done
Since CupidDB was built to handle large dataframe caching, I structured the benchmark around reading dataframes from cache. Here’s how the test was set up:- Dataframes Setup: We created 32 large dataframes, each with 5,000 rows and 1,000 columns, representing a substantial load. Each dataframe was stored under a unique key in each caching system.
- Scenarios Tested: Four main scenarios were considered:
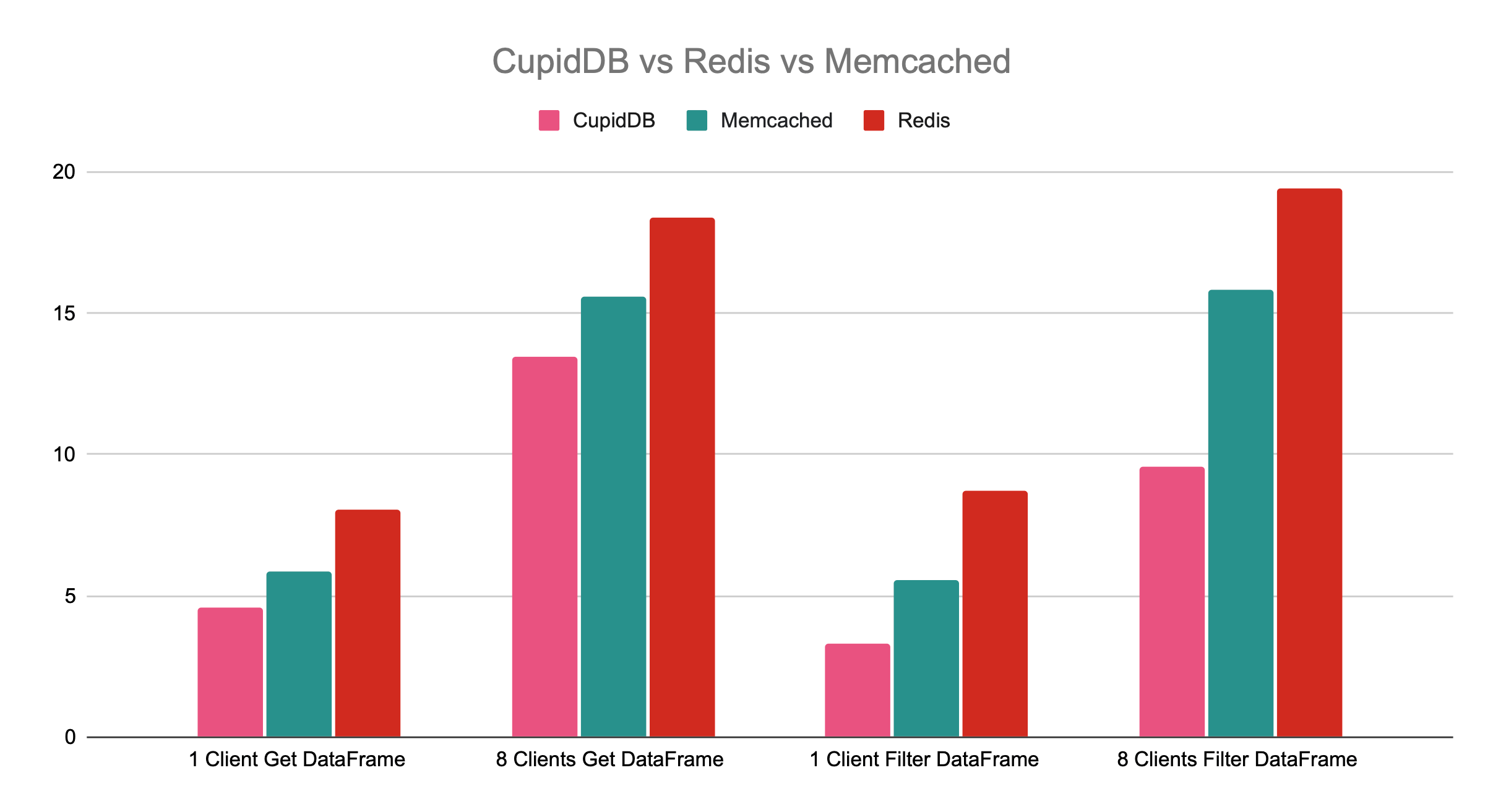
- 1. 1 client retrieving a dataframe
- 2. 8 clients retrieving dataframes concurrently
- 3. 1 client filtering dataframes before retrieval
- 4. 8 clients filtering dataframes concurrently
- Benchmark Details: Each client performed 100 random get requests for dataframes, simulating a realistic cache access pattern.
 (Lower is better)
(Lower is better)Results
The benchmark revealed that CupidDB outperformed Redis and Memcached in all four scenarios. Here’s a summary of the findings:- 1. 1 Client Retrieving Dataframes: CupidDB was the fastest, although the reason is not entirely clear since no concurrency was involved. This scenario purely tested data retrieval speed.
- 2. 8 Clients Retrieving Dataframes Concurrently: CupidDB maintained its performance lead even with multiple clients, showing robust scaling capabilities.
- 3. 1 Client Filtering Dataframes: While Redis and Memcached performed similarly here, CupidDB outpaced both. Despite performing server-side filtering computations, CupidDB benefited from reducing the amount of data transferred.
- 4. 8 Clients Filtering Dataframes Concurrently: CupidDB continued to excel, even with multiple clients and filtering involved. Redis and Memcached showed no performance gain or reduction here, but CupidDB was markedly faster.
Why CupidDB is Faster in Retrieving Dataframes
The superior performance of CupidDB in single-client data retrieval is an intriguing result. Since there’s no concurrency to account for, the speed difference likely stems from CupidDB's optimized data handling. CupidDB stores and transfers data in the native Apache Arrow format, while Redis and Memcached need to pickle and unpickle dataframes during storage and retrieval. This native handling reduces processing overhead for CupidDB and could be one of the primary reasons for its lead.
Additionally, CupidDB’s implementation in Rust, a language known for its low-level speed and efficiency, may further contribute to its fast retrieval times. As a specialized caching solution with fewer features, CupidDB is highly optimized for this specific purpose, unlike Redis and Memcached, which are more generalized caching systems.
Concurrency and Multi-Client Performance
In the concurrent access scenarios (eight clients), CupidDB’s lead over Redis and Memcached remained strong, showing that it scales well with additional client load. The efficient memory handling and concurrency models in Rust likely play a significant role here, allowing CupidDB to maintain high throughput even with multiple requests.
Filtering Dataframes: CupidDB’s Standout Feature
Filtering dataframes was the highlight of the benchmark, where CupidDB truly showcased its unique capability. CupidDB allows server-side filtering, meaning it processes filter conditions directly on the server before sending the filtered data back to the client. In contrast, Redis and Memcached can only return the full dataframe, requiring the client to handle any filtering.
Despite adding computation on the server, CupidDB’s performance in filtering was faster than the other two databases. The filtering computation was so efficient that the reduced network data transfer outweighed any processing delay. This benefit scaled even with eight clients, underscoring CupidDB’s ability to handle intensive server-side filtering requests.
The Power of Filtered Result Caching
CupidDB has an additional feature that wasn’t utilized in this benchmark: caching filtered results. If enabled, this would allow CupidDB to retrieve frequently requested filtered results even faster, likely further widening the performance gap with Redis and Memcached. While this feature was deliberately omitted to highlight raw filtering performance, it’s worth noting that this capability could significantly boost real-world applications where certain filtered dataframes are accessed frequently.
Conclusion
The benchmark results demonstrate that CupidDB is a powerful option for caching dataframes, surpassing Redis and Memcached in both retrieval and filtering scenarios. Its efficient use of Apache Arrow, Rust’s speed, and server-side filtering make it an ideal choice for applications with high dataframe access and processing needs. If you’re working with dataframes and need a fast, optimized caching solution, CupidDB is worth considering. And with its ability to cache filtered results, CupidDB is poised to redefine what high-performance caching can achieve.
Watt Iamsuri
2024-11-11